
2021-02-04
Column
SMN株式会社 a.i lab. のVALIS Cockpitチームで学生インターンをしている松井です。
今回は行列分解ベースの自然言語データ探索アルゴリズムであるCMFにAdamを導入しようとしたところ、特定の場合以外は収束が遅くて使えなかったという話をご紹介いたします。
文書から潜在的な意味を抽出する手法としてトピックモデルがあります。LDAやNMFをはじめとするトピックモデルはシンプルなものの、汎用性や解釈性が高い強力な手法として知られています。
SMN a.i lab. では、NMFを拡張したトピックモデルのライブラリとして pycmfを公開しています。このライブラリは文書に特定のラベルが付与されている状況でのトピックモデルを可能にします。詳しい特徴や利用方法などは過去の記事をご覧ください。
このライブラリでは pycmf の名の通り、複数の行列分解を同時に行うCMF[1]というアルゴリズムを採用しております。行列分解とは、ある行列Xを二つの低ランク行列U,Vで近似する手法で、
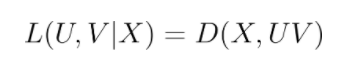
のように定義される損失Lを最小にするU,Vを見つけることで達成されます。ここでDは任意のダイバージェンスを表します。Xに正規分布を仮定すれば単純な最小二乗誤差、Xにベルヌーイ分布を仮定すれば Cross Entropy が採用されます。CMF では複数の行列X, Yに対して同時にこの行列分解を行います。例えば二つの行列を分解する場合、損失はハイパーパラメータで重み付けされた、
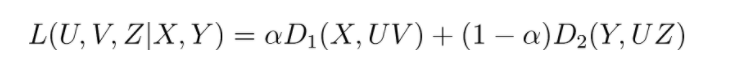
となります。
さて、上記の損失を最小化すれば目的が達成されますが、これは無制約の連続最適化問題であるため 、pycmf ではこれを SGD で計算しています(厳密に言えば 最急降下法) 。しかし、昨今の 損失関数のオプティマイザには迷わず Adam が選ばれることが多いのではないかと思います。 Adam は、モーメンタムの活用やパラメータごとの学習率減衰を行うことによって、
などのメリットがあると言われております[2]。しかし、 pycmf ではAdam は採用されていませんでした。
そこで今回は、CMFにAdamを導入するとSGDより収束が早くなるのかについて調査を行いました。pycmfではオプティマイザを入れ替えることが難しかったため、改めてtensorflowでcmfを再実装し、オプティマイザ以外の条件を一致させて実験しました。今回用いたソースコードはこちらで公開しています。
まずは、SGDと比較して収束が早くなるのかを、過去記事と同様にToxic Commments Classification Challengeの公開データセットで実験してみます。(前処理も同じ)
Toxic Comments Classification Challengeデータセットでは、Wikipediaのtalk pageのコメントに有害かどうかのラベルが付与されています。
つまり、(コメント × 単語)の行列 Xと (コメント × ラベル) のベクトル Yをデータとして利用できます。CMFをこのデータに適用すると、(コメント × 単語)の行列 X を 低次元行列 W, Hの積で表すタスク(Matrix Factorization)と、 (コメント × ラベル) のベクトル Yを 低次元行列 W, Z の積で表すタスク(Logistic Regression)を同時に行うことになります。( D1(WH, X) には二乗誤差を、D2(WZ, Y)には Cross Entropy を設定)
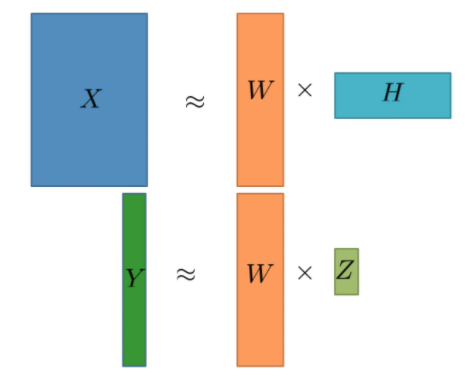
これにより、有害なコメントがもつトピックを抽出することが可能になります。
ではSGDとAdamの比較結果をみていきたいと思います。以下の図は、Adam と SGD の学習曲線を表しています。(横軸がエポック数 、縦軸が目的関数)
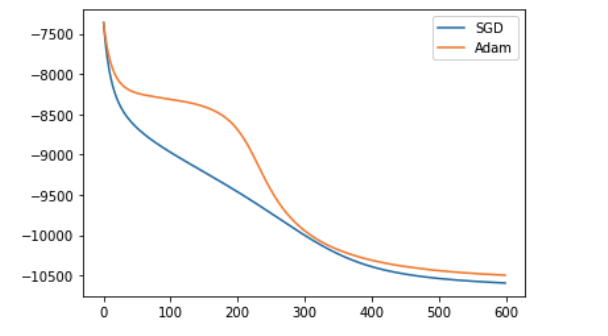
驚くべきことに、過去記事と同じ条件で実験してみたところAdamの方が性能が悪いことがわかりました。そこで、パラメータ数が増えたときにどのような反応があるかを見るために埋め込み次元数を変えて実験してみました。
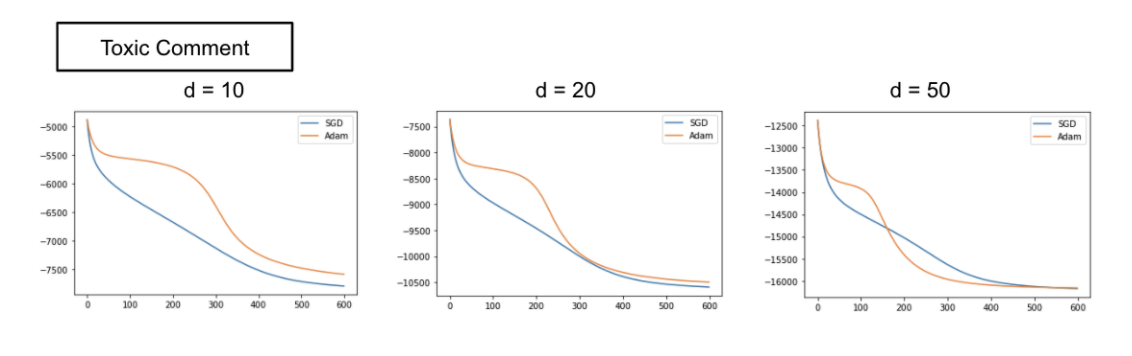
この結果から、埋め込み次元数d を大きくするほど Adam が、小さくするほど SGD が優れていることがわかりました。Adam は Deep Learning などのパラメータ数が多く鞍点が発生しやすい場合に有効であると言われており、その性質と一致しています。
単純に次元数が大きければAdamが強いのか?
上記の結果は埋め込み次元数のパラメータによって2手法の収束に差が出ています。
しかし上記の実験だけでは、
のどちらを示すのかはわかりません。
ただし、データセットの中の真のトピック数を知ることは不可能です。そこで今回は LDA の生成過程に倣って人工データを作成することで、真のトピック数が変化した場合の挙動を調べることができるようにしました。
人工データでの実験方法
まずは文書の人工データの生成方法について説明します。
トピックモデルの検証となるので、基本的にはLDA (Latent Dirichlet allocation) の生成過程に則ります。LDAは以下のような生成過程を仮定して文書の潜在的なパラメータを推定する手法です。今回は逆にこの仮定を人工データ生成に利用します。
(下図はwikipediaより引用)
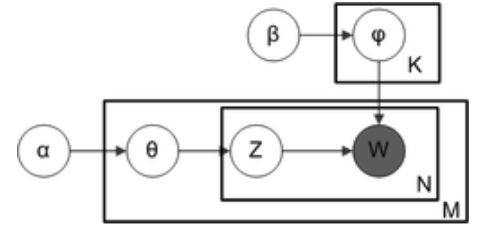
具体的には、以下の手順で人工データを生成しました。

この方法によって生成される行列X は 真のトピック数がKの文書の BoW だと言えます。
ただし、 CMF では文書にラベルが付与されたデータを扱います。そこで、ラベルごとにハイパーパラメーター α が異なる人工データを結合させることでラベルごとのトピック分布の差を表現しました。また、スパース性、文書の長さ、単語の登場回数の要素が Toxic Comment データとおおよそ近いデータを生成しました。詳細な実装はこちらで公開しております。
上の手順で生成した人工データを用いて
を調べます。
1. 真のトピック数を変化させたときの性能
それでは早速、結果を見ていきます真のトピック数 K を 10, 50 のそれぞれについて、埋め込み次元数 d = 10, 20, 50 とした場合の結果が以下のようになりました。
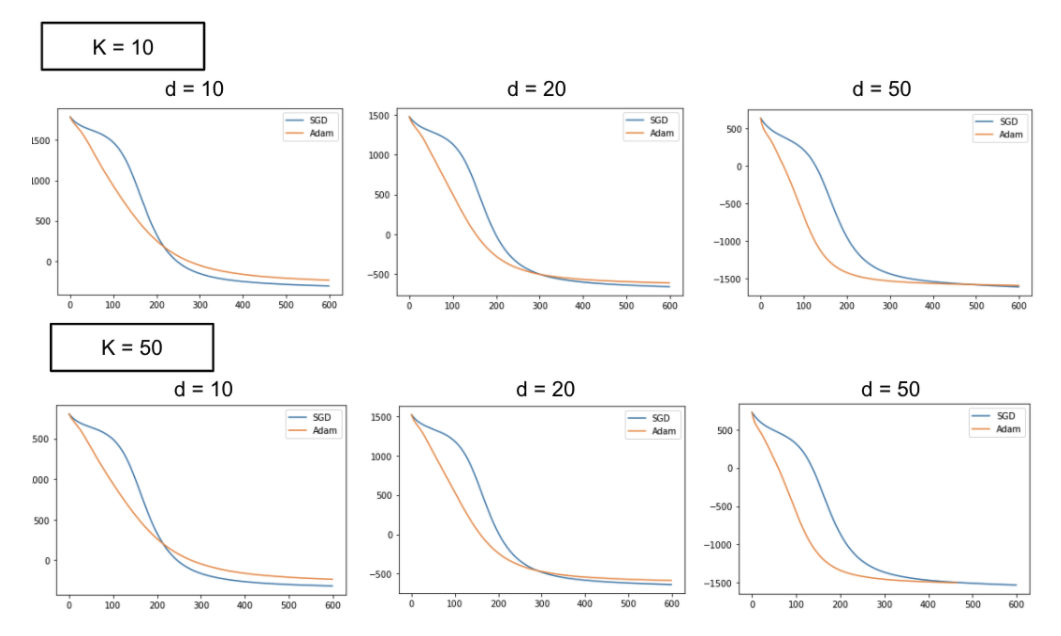
当然実データの方がノイズが大きいため学習曲線の形状は異なっていますが、人工データも埋め込み次元数d を大きくするとSGDと Adam の優劣が逆転するという結果が得られ、その点では一貫性がみられます。
また、意外なことに、真のトピック数を変化(上段・下段で比較)させてもほとんど学習曲線が変わらないということがわかりました。よって、どれだけ文書内にバリエーション豊かな文脈があったとしても、CMF においては埋め込み次元数dが大きいほど Adam 、小さいほど SGD が良いと言えます。
2. 真のトピック数を変化させたときのタスクごとの性能
今回、Toxic Commentデータセットに適用したCMFの損失は
(コメント × 単語)の行列 X の Matrix Factorization + (コメント × ラベル) のベクトル YのLogistic Regression
のようにMatrix Factorization と Logistic Regression の2つの損失の加重和で構成されます。
CMFは一般に複数のタスクの和で構成されるため、どちらのタスクが影響を与えているのかが気になります。
そこで、真のトピック数を変化させたときに、どちらのタスクの損失が支配的になるのかを調査しました。以下の図はK =10 におけるd=10, 50 の二つの条件において、行列 X の Matrix Factorization と ベクトルY の Logistic Regression の損失を別々にプロットした学習曲線を表しています。(左がX、右がY)
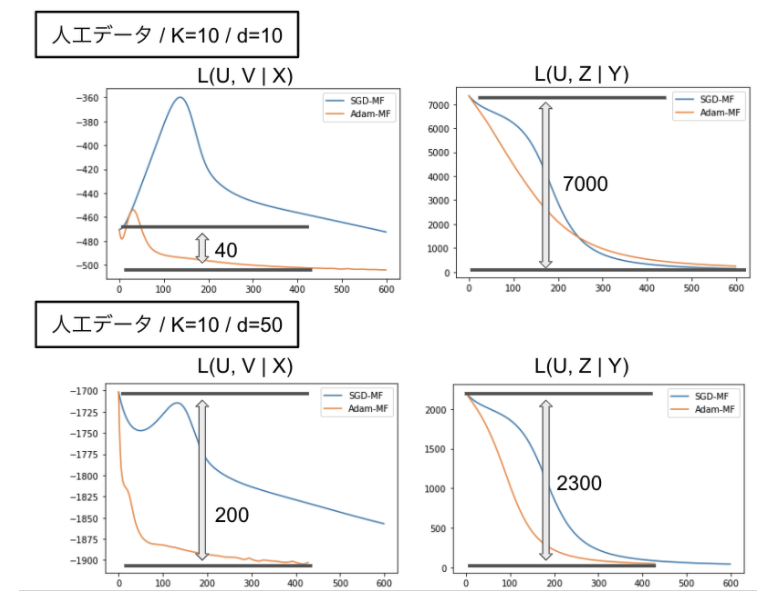
Matrix Factorizationタスクでは真のトピック数によらずAdamが優れていることがわかります。しかし、初期の損失と収束後の損失の差を考えると、Logistic Regressionタスクが支配的です。この結果から、(コメント × ラベル) のLogistic Regressionタスクにおいて、埋め込み次元数dを大きくするにしたがってAdamが性能を発揮し始めたため全体の性能が逆転したことがわかります。
以上の結果をまとめると、
という状況ではAdamが威力を発揮しそうです。ただしトピックの解釈性が重要視されるケースでは埋め込み次元数を大きく設定しないでしょうし、カテゴリ変数がないことの方が珍しいため、 SGDで十分なケースは多いと思われます。
今回は文書データに関する検証を行いましたが、レコメンドシステムなどの教師あり学習として CMF を用いる場合でも同じ結果が得られるかは別に検証が必要です。仮に同じ結果が得られるとすると、これらのタスクでは解釈性以前に損失を下げる必要が出てくるため、埋め込み次元数をある程度大きくして Adam を使うことが有効になるかもしれません。
今回はオプティマイザ以外の条件を統一するために CMF を tensorflow で実装しなおし、AdamとSGDの比較実験を行いました。特に、文書内の真のトピック数と埋め込み次元数に着目し、実データと人工データを用いた検証を行いました。その結果、真のトピック数に関わらず埋め込み次元数のパラメータが大きいところでしかAdamが活躍しないということがわかりました。
筆者自身、何も考えずに Adam を採用してしまうことが多かったのですが、常にAdamが良いわけではないという結果が得られ、いい教訓になったなと思いました。また、アルゴリズムの特性を掴む上で、人工データを生成して実験することの難しさとその重要性を実感しました。今後は momentum の導入や Adadelta など他のオプティマイザでの比較、推薦システムのような欠損値補完のタスクでの検証などもできたらと思います。
以上、ご覧いただきありがとうございました。
参考文献
[1] Relational learning via collective matrix factorization.(KDD2008)
[2] Adam: A method for stochastic optimization.(2014)
以下問い合わせフォームよりお願いします